
داخل عقل الذكاء الاصطناعي: الجمال الخفي للشبكات العصبية مع نماذج DeepSeek R1 و Llama
داخل عقل الذكاء الصناعي
عندما نتفاعل مع نماذج الذكاء الصناعي مثل ChatGPT وLlama وDeepSeek، نتعامل مع أنظمة تحتوي على مليارات المعلمات - ولكن ماذا يعني ذلك فعلا؟ اليوم، سنغوص عميقاً في كيفية بناء هذه الشبكات العصبية الضخمة وسنستكشف طرق مدهشة لتصوير آلياتها الداخلية.
في جوهرها، النماذج اللغوية هي شبكات معقدة من الخلايا العصبية الصناعية المترابطة. كل اتصال بين هذه الخلايا له وزن، وهو ما نسميه بمعلمة. هذه الأوزان تحدد كيفية تدفق المعلومات عبر الشبكة وتؤثر في النهاية على نواتج النموذج. عندما نقول أن نموذج مثل Llama-3 لديه 70 مليار معلمة، نتحدث عن 70 مليار رقم فردي يعملون معًا لمعالجة وإنشاء النصوص.
هذه المعلمات ليست أرقامًا عشوائية - بل هي معدلة بعناية من خلال التدريب للتعرف على الأنماط في اللغة. فكر فيها كأزرار صغيرة يقوم النموذج بتعديلها أثناء التعلم، كل واحدة منها تساهم في فهمه للغة والسياق والمعنى. يتم تخزين هذه المعلمات في ملفات tensor.
يتم تخزين مليارات المعلمات في النماذج اللغوية في ملفات متخصصة تسمى ملفات tensor (عادة مع امتداد .safetensors). تنظم هذه الملفات المعلمات في مصفوفات متعددة الأبعاد، بطريقة مشابهة لكيفية تنظيم الجداول البيانات في الصفوف والأعمدة، ولكن مع القدرة على التوسع في أبعاد متعددة. بينما لا يكون دور كل مصفوفة ذا صلة بهذا التجربة القصيرة التي نقوم بها، من المهم أن نلاحظ أن كل مجموعة من المصفوفات (ضمن ملفات tensor) لها وظيفة مميزة في بنية LLM.
هذه هي الملفات التي سنحاول تصويرها. تقنيات التصوير النموذجية للشبكات العصبية هي: الرسوم البيانية الخطية، الرسوم البيانية التاريخية، رسوم الشبكة، الرسوم البيانية ثلاثية الأبعاد وخرائط الحرارة. من بين هذه الخيارات، للتمرين الحالي، اخترنا خرائط الحرارة.
تستخدم تصوير خرائط الحرارة هذه البنية المصفوفة بشكل خاص لإظهار أنماط الأوزان، حيث:
- كل صف يمثل معلمة
- كل عمود يمثل بُعد
- القيم في الخلايا هي الأوزان الفعلية
لنبدأ بنموذجنا الأول للتحليل: Llama 3.2 - 3B معلمات. في البداية، يمكننا أن نلاحظ بشكل أساسي نمط "الضوضاء" دون ظهور أنماط مميزة.
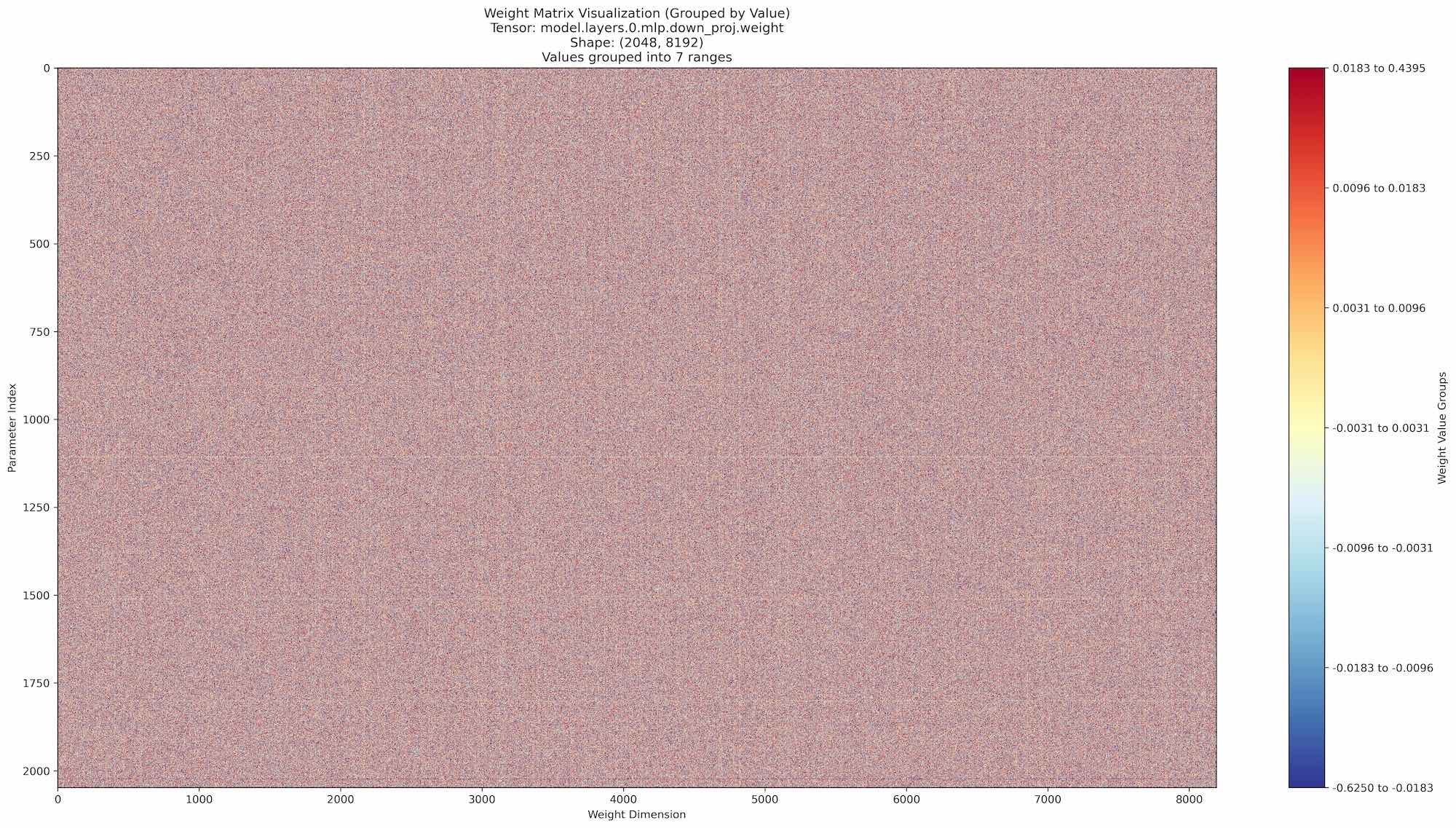
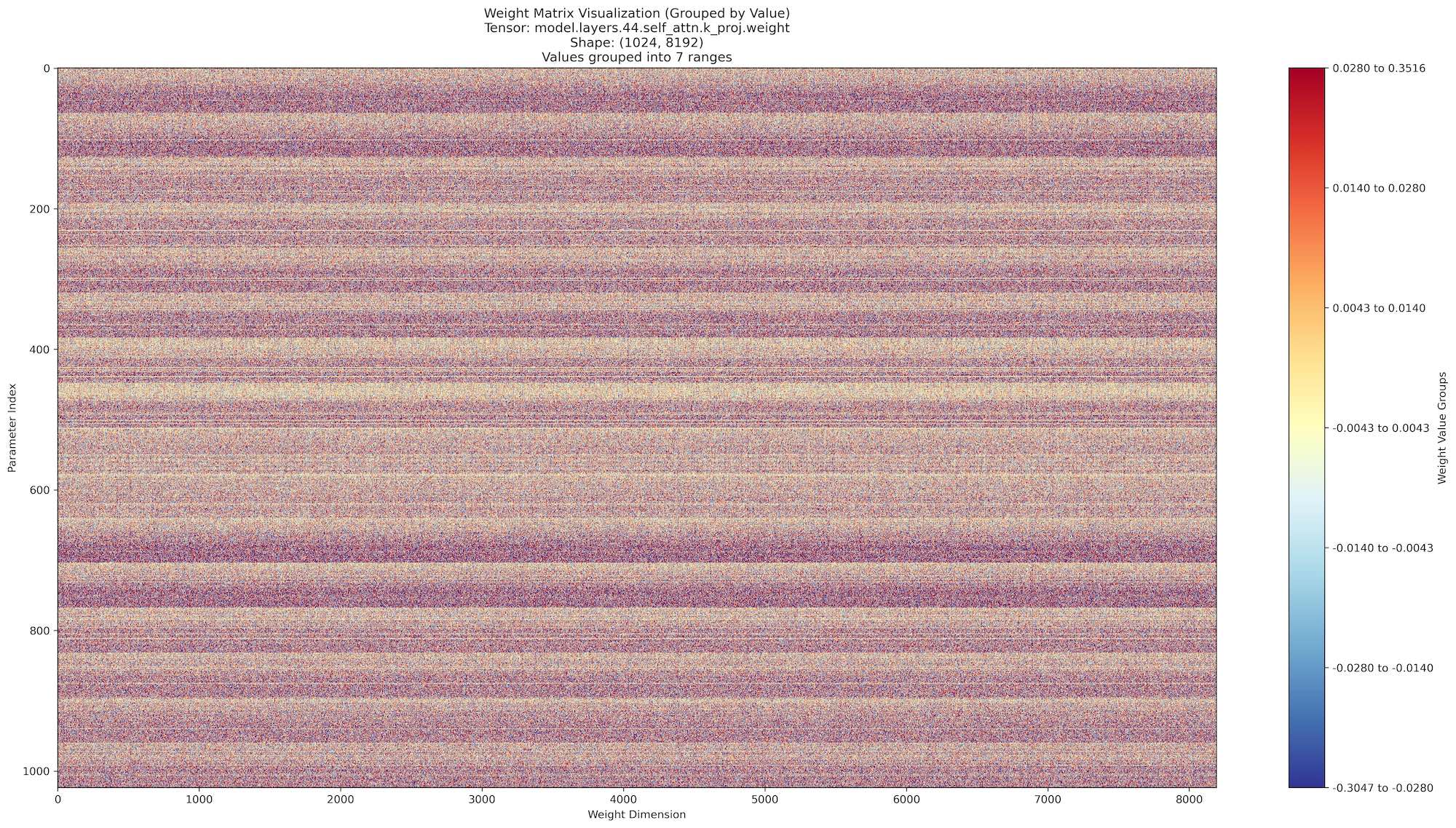
دعونا ندرس نموذج بمعاملات أعلى قليلاً، لاما 3.3 - 70B. بينما يستمر نمط الضوضاء، يمكننا ملاحظة بعض الأنماط الخفية التي تظهر على شكل خطوط عمودية وأفقية. هذه الأنماط مثيرة بصرياً، ولكنها ليست بعد كافية لتحليل معنوي.
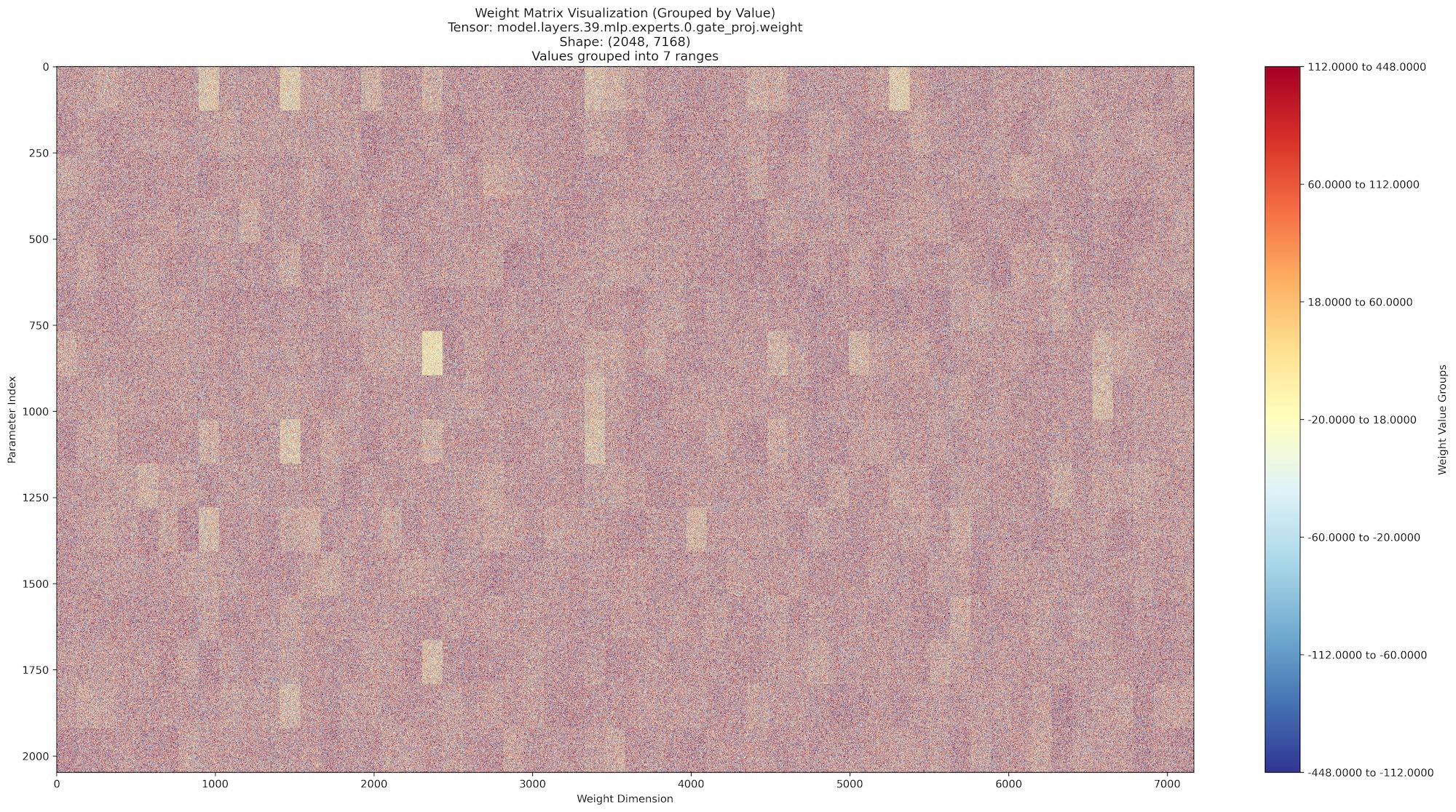
تركز التحليل الأخير على أكبر نموذج مفتوح المصدر متاح في وقت كتابة هذا المنشور: DeepSeek - R1 (الإصدار 3). في هذه المرحلة، تصبح المرئيات أكثر إثارة للاهتمام بشكل ملحوظ. نلاحظ ظهور أنماط مستطيلة مميزة داخل مرئيات ملف التنسور، مما يشير إلى تنظيم أكثر هيكلة لمعلمات النموذج.
تثير هذه التشكيلات المستطيلة سؤالًا مثيرًا للاهتمام: هل يمكن أن تشير إلى نوع من "الذكاء البصري" القابل للقياس داخل هذه النماذج؟
بينما يكون من الجذاب القيام بالاستنتاجات، يجب أن نظل حذرين في تفسيرنا. بدون الوصول إلى نماذج ذات عدد أكبر من المعلمات للمقارنة، من السابق لأوانه القول بشكل قاطع حول ما تعنيه هذه الأنماط. ومع ذلك، توفر هذه الملاحظات ختامًا مثيرًا لاستكشافنا التجريبي.
إذا كنت مهتمًا برؤية هذه المرئيات في العمل، فقد أنشأ الرئيس التنفيذي لشركتنا فيديو قصير يشرح هذا التحليل، الذي يمكنك العثور عليه هنا.
هل أنت مستعد لتحويل أعمالك باستخدام حلول الذكاء الاصطناعي المخصصة؟
في Softescu، نحن متخصصون في تطوير تطبيقات الذكاء الاصطناعي الذكية التي تفهم احتياجات أعمالك الفريدة. يمكن لفريقنا من مهندسي الذكاء الاصطناعي وخبراء التعلم الآلي مساعدتك في استغلال قوة نماذج اللغة الكبيرة والذكاء الاصطناعي المحادثي مع ضمان التكامل السلس مع أنظمتك الحالية. سواء كنت تبحث عن تشغيل العمليات أو تحسين تجارب العملاء أو الحصول على رؤى أعمق للأعمال، فاتصل بنا للحصول على استشارة حلول الذكاء الاصطناعي المخصصة.
